- Record: found
- Abstract: found
- Article: found
A Deep Learning Approach for Missing Data Imputation of Rating Scales Assessing Attention-Deficit Hyperactivity Disorder
Read this article at
Abstract
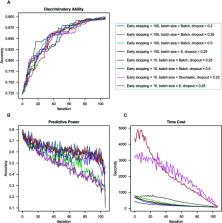
A variety of tools and methods have been used to measure behavioral symptoms of attention-deficit/hyperactivity disorder (ADHD). Missing data is a major concern in ADHD behavioral studies. This study used a deep learning method to impute missing data in ADHD rating scales and evaluated the ability of the imputed dataset (i.e., the imputed data replacing the original missing values) to distinguish youths with ADHD from youths without ADHD. The data were collected from 1220 youths, 799 of whom had an ADHD diagnosis, and 421 were typically developing (TD) youths without ADHD, recruited in Northern Taiwan. Participants were assessed using the Conners’ Continuous Performance Test, the Chinese versions of the Conners’ rating scale-revised: short form for parent and teacher reports, and the Swanson, Nolan, and Pelham, version IV scale for parent and teacher reports. We used deep learning, with information from the original complete dataset (referred to as the reference dataset), to perform missing data imputation and generate an imputation order according to the imputed accuracy of each question. We evaluated the effectiveness of imputation using support vector machine to classify the ADHD and TD groups in the imputed dataset. The imputed dataset can classify ADHD vs. TD up to 89% accuracy, which did not differ from the classification accuracy (89%) using the reference dataset. Most of the behaviors related to oppositional behaviors rated by teachers and hyperactivity/impulsivity rated by both parents and teachers showed high discriminatory accuracy to distinguish ADHD from non-ADHD. Our findings support a deep learning solution for missing data imputation without introducing bias to the data.
Related collections
Most cited references76
- Record: found
- Abstract: found
- Article: not found
Applications of Support Vector Machine (SVM) Learning in Cancer Genomics
- Record: found
- Abstract: found
- Article: not found
Estimating causal effects from epidemiological data.
- Record: found
- Abstract: found
- Article: not found