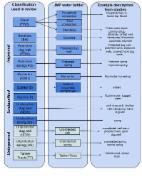
Introduction The importance of water to human health and wellbeing is encapsulated in the Human Right to Water and Sanitation, which entitles everyone to “sufficient, safe, acceptable physically accessible and affordable water for personal and domestic uses” [1], as reaffirmed by the United Nations General Assembly and Human Rights Council in 2010 [2]. Millennium Development Goals (MDGs) Target 7c aims “to halve the proportion of the population without sustainable access to safe drinking-water …” [3], a step towards universal access. “Use of an improved source” was adopted as an indicator for monitoring access to safe drinking-water globally (Table 1) and relies on national censuses and nationally representative household surveys as the primary sources of data. 10.1371/journal.pmed.1001644.t001 Table 1 Types of improved source and the estimated proportion of the global population using these as their primary source of drinking-water. Source Categorya Description Global Population Using Water Source in 2010b (%) Urban Rural Total Household or yard connection Piped water into dwelling, also called a household connection, is defined as a water service pipe connected with in-house plumbing to one or more taps. Piped water to yard/plot, also called a yard connection, is defined as a piped water connection to a tap placed in the yard or plot outside the dwelling. 80 29 54 Standpipe Public tap or standpipe is a public water point from which people can collect water. A standpipe is also known as a public fountain or public tap. Public standpipes can have one or more taps and are typically made of brickwork, masonry, or concrete. 6 8 7 Borehole Tubewell or borehole is a deep hole that has been driven, bored, or drilled, with the purpose of reaching groundwater supplies. Boreholes/tubewells are constructed with casing, or pipes, which prevent the small diameter hole from caving in and protects the water source from infiltration by runoff water. 8 30 18 Protected dug well Protected dug well is a dug well that is protected from runoff water by a well lining or casing that is raised above ground level and a platform that diverts spilled water away from the well. A protected dug well is also covered, so that bird droppings and animals cannot fall into the well. 2c 10c 6c Protected spring The spring is typically protected from runoff, bird droppings, and animals by a “spring box,” which is constructed of brick, masonry, or concrete and is built around the spring so that water flows directly out of the box into a pipe or cistern, without being exposed to outside pollution. 100, “high risk” or “very high risk” [24],[25]. However FIB are imperfect and their level does not necessarily equate to risk [26]; since quality varies both temporally and spatially, occasional sampling may not accurately reflect actual exposure. A complementary approach in safety assessment is the identification of hazards and preventative risk management measures through “sanitary inspection” of a water source and its surroundings [24],[27]. The improved source indicator is in effect a very simplified form of sanitary inspection. Like FIB, sanitary inspections have long been a tool in assessing drinking-water safety. In 1904, Prescott and Winslow stated, “[t]he first attempt of the expert called in to pronounce upon the character of a potable water should be to make a thorough sanitary inspection…” [28]. Standardized forms can be used to assess sanitary risk and derive a summary measure, the sanitary risk score. These forms typically include questions about the integrity of protective elements, such as fencing or well covers, and the proximity of hazards such as latrines; forms are available for different types of water source. Like water quality, some sanitary risk factors may vary spatially and temporally. The approach can be combined with microbiological analysis, either to yield a risk cross-tabulation [24],[25] or as a part of a more detailed Water Safety Plan [29]. In January 2012, WHO and UNICEF established working groups to develop targets and indicators for enhanced global monitoring of drinking-water, sanitation, and hygiene post-2015. The water working group proposed to continue using the improved water source classification as part of a revised set of indicators for assessing progressive improvements in service [30]. This review was commissioned to assist the group in evaluating the evidence linking improved source types and health-related indicators of water quality. The following specific questions were considered in order to determine the potential and limits of classification by source type in assessing safety in future global reporting: (i) Is water from improved sources less likely to exceed health-based guidelines for microbial water quality than water from unimproved sources? (ii) To what extent does microbial contamination vary between source types, between countries, and between rural and urban areas? (iii) Are some types of water source associated with higher risk scores as assessed by sanitary inspection? Methods We conducted a systematic review of studies of fecal contamination of drinking-water in LMICs in adherence with PRISMA guidelines (Text S1) [31]. The protocol for the review is described in Protocol S1. Search Strategy Studies were identified from both peer-reviewed and grey literature. To identify peer-reviewed literature, the topic “water quality” was combined with terms to restrict the search to drinking-water and either a measure of microbial water quality (e.g., “coli”) or sanitary risk (e.g., “sanitary inspection”). We further restricted the search to LMICs using a list of country names based on the MDG regions [32]. Online databases were searched including PubMed, Web of Science, and the Global Health Library. Grey literature was sourced from a variety of sites including those used in previous drinking-water–related reviews [33]–[35]. Translated search terms (Chinese, French, Portuguese, and Spanish) were used to identify additional studies. An email requesting submissions of relevant studies was distributed to water sector professional networks. We searched bibliographies of included studies and contacted authors where full texts could not be obtained through other means. Searches were conducted between 7th January and 1st August 2013. Eligibility and Selection Studies were included in the review provided they: reported on water quality, at either the point of collection or consumption, from sources used for drinking that would not be classified as surface waters by the JMP; contained extractable data on TTC or E. coli with sample volumes not less than 10 ml; were published between January 1990 (the baseline year for MDG targets) and August 2013; included results from at least ten separate water samples from different water sources of a given type or, in the case of piped systems, individual taps, and in the case of packaged waters, brands; reported data from LMICs as defined by the MDG regions [32] (thereby excluding 55 high-income countries, comprising 18.1% of the global population in 2010 [36]); were published in languages spoken by at least one author (Chinese, English, French, Portuguese, or Spanish); and included sufficient detail about the water sources and associated results with a water source with sufficient detail to be categorized (refer to Figure 1 for details). Other indicators such as coliphage and direct pathogen detection are not as widely used and are not included in this review [37]. We did not include studies that only assessed surface waters as these are generally considered unfit for drinking. We included bottled water and sachet water that do not form part of the JMP improved source classification (which is concerned with the household's primary source of water for drinking, cooking, and personal hygiene [38]) but are nonetheless important sources of drinking-water in many countries. 10.1371/journal.pmed.1001644.g001 Figure 1 Matching drinking-water source types to the classification used by the Joint Monitoring Programme. Independent primary screening of English language titles and abstracts for studies was conducted by two authors (RB and RC). If any reviewer selected a study, we referred to the full text. Data from eligible studies were extracted into a standardized spreadsheet and 10% of the English language texts were subjected to independent quality control by a second author (RB and RC). Screening and extraction of data in other languages was conducted by one author (RB or HY). Data Extraction and Matching Where possible we extracted or calculated the following information for each type of water source in the studies: (i) total number of samples and proportion containing E. coli or TTC; (ii) proportion of samples within microbial risk categories ( 100 E. coli or TTC per 100 ml); (iii) geometric mean, mean, or median levels of E. coli or TTC; and (iv) risk categories according to the sanitary inspection (“low,” “medium,” “high,” and “very high” risk) as reported in the studies. For intervention studies (other than the provision of an improved source, for example the protection of unprotected springs), estimates could be based on either the baseline or control group; when both were available we used whichever had the largest sample size. For studies reporting both E. coli and TTC, we used only the E. coli results. Where repeated measures were taken at the same source and data permitted we extracted the lowest compliance level (e.g., wet season data) with WHO Guideline values as well as the overall proportion of samples containing FIB. We identified countries as “low,” “lower middle,” “upper middle,” and “high” income using the 2013 World Bank classification [39]. We recorded whether studies took place during or shortly after emergencies or natural disasters and if they were in non-household settings such as schools and health facilities. We identified additional study characteristics expected to influence water quality, including the setting (urban/rural), season (wet/dry or period of sampling), and study design [34]. Each type of water source in a given study was classified as improved or unimproved and matched to a specific water source type following the classification used in household surveys including the Demographic and Health Surveys [38]. We recorded whether samples had been taken directly from the water source or after storage, for example in the home. Where the appropriate match could not be determined, our approach differed depending on the type of source. We grouped groundwater sources from studies that did not distinguish between protected and unprotected (unclassified dug well, unclassified spring) and we created groups for studies of other sources such as bottled and sachet water. Further information about the matching is available in Figure 1. Study Quality and Bias Studies were rated for quality on the basis of the criteria summarized in Table 2. A quality score between 0 and 13 for each study was determined on the basis of the number of affirmative responses. We also categorized studies on the basis of anticipated susceptibility to bias in estimating the compliance to health-based guidelines and the extent of microbial contamination; our categories were: case-control or cohort, intervention, diagnostic study, cross-sectional survey, and longitudinal survey. Any study of at least 6 months duration and more than two samples at each water point was categorized as longitudinal. We identified studies where authors indicated whether selection was intended to be representative or selection had been randomized. 10.1371/journal.pmed.1001644.t002 Table 2 Quality criteria used to assess studies of microbial water quality. Criterion Question Selection described Do the authors describe how the water samples were chosen, including how either the types of water source or their users were selected? Selection representative Did the authors detail an approach designed to provide representative picture water quality in a given area? Selection randomized Was sampling randomized over a given study area or population? Region described Does the study report the geographic region within the country where it was conducted? Season reported Were the seasons or months of sampling reported? Quality control Were quality control procedures specified or referred to? Method described Are well-defined and appropriate methods of microbial analysis described or referenced? Point of sampling Was the point at which water was sampled well defined? (For example whether the water was collected from within a household storage container or directly from a water source) Handling described Are sample handling procedures described, including sample collection, transport method, and duration? Handling minimum criteria Does sample handling and processing meet the following criteria: transport on ice or between 2–8°C, analysis within 6 hours of collection, and specified incubation temperature? Accredited laboratory Was the microbial analysis conducted in an accredited laboratory setting? Trained technician Do the authors state whether trained technicians conducted the water quality assessments or the analyses were undertaken by laboratory technicians? External review Was the study subject to peer review or external review prior to publication? Analysis Because of the extent of heterogeneity between studies, we chose to plot cumulative density functions (CDFs) of the proportion of samples with detected (>1 per 100 ml) and high (>100 per 100 ml) FIB in each study to compare water source types between studies. This approach has been used in a systematic review of prevalence of schizophrenia [40]. CDFs are used to qualitatively assess the proportion of studies reporting frequent and high levels of microbial contamination. Measures of central tendency from studies were not included in the meta-analysis because of limited reporting of measures of dispersion, inadequate explanation of the handling of censored data, and the difficulty in reconciling diverse reported measures of central tendency (e.g., geometric versus arithmetic mean) [41]. Random effects meta-regression was used to investigate risk factors and settings where fecal contamination is most common and other possible explanations for the observed heterogeneity between studies [42]. A logit transformation is recommended for the analysis of proportions [43] and was applied to both the proportion of samples with detectable (>1 per 100 ml) and high (>100 per 100 ml) levels of FIB. The metareg function in Stata was used after a continuity correction of ±0.5 where the proportion of samples positive was zero or one [44], and we estimated the within study variance for each proportion as the reciprocal of the binomial variance [45]. Subgroup analysis included variables defined a priori (including water source type, rural versus urban, and income-level) and defined a posteriori (for example if piped water had been treated prior to distribution). We separately evaluated piped and other improved sources for those variables reaching significance at the 5% level in bivariate analysis for all source types. Studies that included both improved and unimproved sources were then combined using meta-analysis with the odds ratio (OR) as the effect measure. We calculated a pooled estimate of the protective effect of an improved source and corresponding confidence intervals using the metan function in Stata. We then assessed the influence of small study bias by the funnel plot method and performed an Egger's test using a normal likelihood approximation. The extent of heterogeneity in protective effect was determined using Higgins I2 and corresponding confidence intervals were calculated [42]. Calculations were performed in Stata 13SE. Results Search Results As shown in Figure 2, in total, 6,586 reports were identified through database searches. A further 1,274 reports were identified from grey literature and correspondence with experts. Most studies were excluded because they did not test water that was clearly used for drinking, did not associate results with a water source type, or did not include enough different water sources or in the case of packaged water, brands. Studies often did not provide an adequate description of the water sources to allow them to be matched to the JMP source categories; this limitation was particularly the case for ground water sources. For example, several studies reported results for “hand pumps” (a description of the technology above ground) but did not provide details about well construction. Although these may often be boreholes, hand pump conversions are also applied to dug wells. Other studies simply described water sources as “wells” or “springs.” Some studies provided details that are not captured in the JMP classification, such as whether water from a piped supply had been treated. Full texts could not be obtained for 99 potentially relevant reports, many of which were conference presentations and most of which were identified from bibliographies. The remaining 310 reports [6],[24],[46]–[353] were incorporated in our review and provide information on 96,737 water samples. The total number of studies is higher (319) due to a small number of multi-country reports. On average each study provides information on 1.7 water source types, resulting in a database with 555 datasets (Dataset S1). 10.1371/journal.pmed.1001644.g002 Figure 2 Flowchart for a review of safety of sources of drinking-water. Study Characteristics Characteristics of included studies are summarized in Table 3. The review is dominated by cross-sectional studies (n = 241, 75%) with fewer longitudinal surveys (n = 39, 12%). Authors report selecting sources or households at random in a minority of studies (n = 68, 21%); most of these studies selected sources randomly within a region or community rather than at national level. The main exceptions were the Rapid Assessment of Drinking-Water Quality (RADWQ) studies commissioned by WHO and UNICEF, of which five have been published [64],[65],[164],[281],[322] and a repeated cross-sectional study in Peru for which only the total coliform results have previously been reported but for which we were able to secure E. coli data [227]. 10.1371/journal.pmed.1001644.t003 Table 3 Characteristics of included studies. Characteristic Studies Datasets Samples Number (%) Number (%) Number (%) Setting Urban 146 (46) 227 (41) 30,038 (31) Rural 130 (41) 243 (44) 34,850 (36) Both urban and rural 41 (13) 83 (15) 31,767 (33) Unclassified setting 2 (1) 2 (0) 82 (0) Emergencies 13 (4) 26 (5) 2,897 (3) Non-household 17 (5) 21 (4) 2,121 (2) Point of sampling Stored water 50 (15) 74 (13) 19,965 (21) Directly from source 293 (92) 481 (87) 76,772 (79) Water supply Improved 209 (65) 273 (49) 56, 268 (58) Piped 118 (37) 119 (21) 32,348 (33) Borehole 83 (26) 83 (15) 11,452 (12) Protected dug well 36 (11) 36 (6) 8,697 (9) Protected spring 11 (3) 11 (2) 978 (1) Rainwater 25 (8) 25 (5) 2,793 (3) Unimproved 62 (19) 71 (13) 5,594 (6) Unprotected dug well 49 (15) 49 (9) 4,577 (5) Unprotected spring 16 (5) 16 (3) 810 (1) Tanker truck 6 (2) 6 (1) 207 (0) Unclassified 167 (53) 213 (38) 35,087 (36) Sachet 15 (5) 15 (3) 1,305 (1) Bottled 35 (11) 35 (6) 2,339 (2) Dug well 49 (15) 49 (9) 4,577 (5) Spring 16 (5) 16 (3) 810 (1) Design Randomized 68 (21) 131 (24) 31,210 (32) Representative 74 (23) 148 (27) 37,614 (39) Cohort or case control 5 (2) 15 (3) 4,114 (4) Intervention 22 (7) 47 (8) 9,799 (10) Cross-sectional survey 241 (75) 404 (73) 48,559 (50) Longitudinal survey 39 (12) 66 (12) 32,302 (33) Diagnostic 12 (4) 23 (4) 1,963 (2) Parameter E. coli 152 (48) 270 (49) 32,298 (33) TTC only 167 (52) 285 (51) 64,439 (67) Language English 276 (86) 502 (90) 81,349 (84) Spanish 6 (2) 8 (1) 3,024 (3) Portuguese 24 (8) 29 (5) 9,146 (9) French 4 (1) 5 (1) 187 (0) Chinese 9 (3) 11 (2) 3,031 (3) Reporting Presence/absence of FIB 287 (90) 499 (90) 90,056 (93) Microbial risk classification 90 (28) 165 (30) 23,953 (25) Mean FIB 80 (25) 136 (25) 15,530 (16) Geometric mean FIB 34 (11) 68 (12) 11,797 (12) Range of FIB 74 (23) 108 (19) 9,407 (10) Standard deviation of FIB 21 (7) 38 (7) 4,417 (5) Sanitary risk 44 (14) 82 (15) 15,808 (16) WHO sanitary risk 12 (4) 31 (6) 9,160 (9) Sanitary risk classification 17 (5) 44 (8) 10,667 (11) Sample Size a Small (n = 10–30) NA 192 (35) 3,711 (4) Medium (n = 31–100) NA 187 (34) 11,615 (12) Large (n = 101–6,021) NA 176 (32) 81,411 (84) Quality b Low (1–5) 113 (36) 199 (36) 27,892 (29) Medium (6–7) 94 (29) 142 (26) 16,980 (17) High (8–13) 112 (35) 214 (39) 51,865 (54) Total 319 (100) 555 (100) 96,737 (100) a Terciles by datasets. b Terciles by study. NA, not applicable. Study quality varied greatly spanning from a quality score of 1 to 12 and with an interquartile range of 5 to 8 (Figure S1). Whereas most studies described the analytical method used to detect E. coli or TTC (80%), how water sources were selected (67%), and the setting in which the study took place (86%), fewer specified quality control procedures (15%), met the basic sample handling criteria (25%), used trained technicians to conduct the water quality tests (15%), or arranged testing in an accredited laboratory (12%) (Figure S2). Most studies were from sub-Saharan Africa, southern Asia, or Latin America and the Caribbean (Figure 3). The majority of included studies investigated water quality at the source. Studies reporting on the quality of water stored in households by provenance were less common (n = 49), and few of these compare quality of stored water with that of the associated source (n = 26). Several studies took place during or after emergencies [97],[201] and natural hazards, including cyclones [235], floods [78],[208], droughts [341], and tsunamis [130],[147],[331]. Non-household settings such as schools and health facilities were addressed in a small number of studies (n = 17). Few studies separately report water quality information from slum or peri-urban settings (n = 7). 10.1371/journal.pmed.1001644.g003 Figure 3 Map of study locations. Qualitative Synthesis In Figures S3 and S4 levels of microbial contamination are shown using the FIB level classification ( 100 FIB per 100 ml), grouped by type of improved water source. These results are broadly in agreement with a comparison using measures of central tendency (Figure S5) and show great variability in the likelihood and extent of contamination between studies and source types. Large studies with random sampling demonstrate marked differences in water quality between countries; for example less than 0.01% of samples from utility piped supplies in Jordan [281] were found to contain TTC compared with 9% to 23% of utility piped supplies in the other four RADWQ countries [64],[65],[164],[322]. Only one national randomized study differentiated between rural and urban areas; the proportion of samples from piped supplies containing E. coli was found to be substantially higher in rural (61%, n = 101) than urban (37%, n = 1470) areas in Peru [227]. In comparison to microbial testing, sanitary inspections are less widely practiced or data are rarely published. Sanitary inspection procedures vary considerably and are usually adapted to the local context; of the 44 studies reporting sanitary inspections only 12 used standardized WHO forms. In Figure S6 the sanitary risk levels as reported in nine studies are compared with the proportion of samples containing FIB and suggest that there is no strong association between these two measures. Between Studies Analysis: CDF and Meta-regression The number of studies reporting high proportions of samples contaminated or high levels of FIB is lower for improved sources as can be seen in Figure S7. Yet, in 38% of 191 studies reporting the quality of improved sources, at least a quarter of samples exceeded recommended levels of FIB. Figure S8 shows CDFs by source type with similar patterns to those from the FIB level classification. Results of the meta-regression are shown in Table 4. We find that country income-level is a significant determinant of water quality and the odds of contamination are 2.37 times (95% CI 1.52–3.72 [p = 0.001]; Table 4) higher in low-income countries compared with wealthier countries. However this result is not significant when separately considering piped and other improved sources (Tables S1 and S2). 10.1371/journal.pmed.1001644.t004 Table 4 Between studies meta-regression. Variables Proportion of Samples >1 FIB per 100 ml Proportion of Samples >100 FIB per 100 ml Obs. OR [95% CI] p-Value Obs. OR [95% CI] p-Value Source type Improved vs. unimproved 291 0.14 [0.08–0.25] 9 out of 13; Figure S1) with description of quality control procedures, meeting handling criteria, and statement of season(s) of sampling most frequently omitted quality factors. Many studies, particularly of groundwaters, were excluded as we could not match water source types or determine whether they were “improved.” At the review level, we may not have identified all studies that meet the inclusion criteria. To capture additional studies would have required the screening of tens of thousands of records, as we were unable to identify more specific search terms. Two sources of water quality information that could be used in future studies and monitoring: regulatory surveillance and utility quality control data are likely to be extensive and not well represented as they may not be published and publicly available. Publicly available data from these sources rarely matched our inclusion criteria, usually because of failure to report sample sizes or associate water quality with source type. We identified few studies in languages other than English despite conducting searches in four other languages, and several regions are underrepresented (Figure 3) including Caucasus and Central Asia and Oceania for which studies may be available in other languages. Since few studies separately report water quality in slums, we combined studies of slum and peri-urban populations with those taking place in formal urban areas and we were therefore unable to investigate intra-urban disparities [7]. There may be a small number of errors in the database; in the 10% of English language studies independent extraction 1 per 100 ml) and high (>100 per 100 ml) E. coli or TTC, by improved and unimproved source. (EPS) Click here for additional data file. Figure S8 Cumulative density function of the proportion of samples containing fecal indicator bacteria in each study for improved (left) and unimproved (right) sources by type. (EPS) Click here for additional data file. Figure S9 Funnel plot for the odds ratio comparing the safety of improved and unimproved sources in a given study. (EPS) Click here for additional data file. Table S1 Between studies meta-regression for piped supplies. (DOCX) Click here for additional data file. Table S2 Between studies meta-regression for other improved sources. (DOCX) Click here for additional data file. Table S3 Variation in microbial safety during the year, findings of included studies for selected source types. (DOCX) Click here for additional data file. Alternative Language Abstract S1 Mandarin Chinese translation of the abstract by Hong Yang. (DOCX) Click here for additional data file. Dataset S1 Database of included water quality studies. (XLSX) Click here for additional data file. Protocol S1 Systematic review protocol. (DOCX) Click here for additional data file. Text S1 PRISMA checklist of items to include when reporting a systematic review or meta-analysis. (DOC) Click here for additional data file.